


1 引言
21世纪以来,随着互联网技术的快速发展,人们面临着前所未有的信息轰炸,如何有效利用和挖掘各种信息资源,获取潜在的、有价值的知识和情报已成为当前的迫切需求。在这些海量的信息中,有相当一部分是无结构的自由文本数据,例如Web网页、学术论文和研究报告等,另外还包括我们经常使用的社交化媒体,如微博、朋友圈中的文本内容。采用常规的数理统计和数据挖掘的方法难以对上述文本数据进行有效的分析和处理,因此文本挖掘技术应运而生。文本挖掘以符号群为基本信息单元,以统计数理分析、计算语言学为基础,结合信息检索技术和机器学习,分解文本内容,关注文本的内容特征,实现对文本细粒度、深层次、全面的分析和处理[1]。而作为文本挖掘领域的新兴技术,主题模型更是弥补了常规文本挖掘方法不能反映词汇间语义关系的缺陷,近年来受到了国内外学者的普遍关注,在文本分类、信息检索、情感分析、话题挖掘等领域获得了广泛的应用。在此背景下,为了整体把握主题模型的研究现状和研究热点,本文从主题模型的基本原理、起源和历史演变出发,采用文献计量学中文献外部特征统计分析和共词分析的方法,从时间趋势、机构分布、核心作者、学科和期刊分布等角度揭示主题模型在国际和国内的研究发展态势,并通过关键词的共现和聚类,归纳总结主题模型的研究热点分布,以期为相关研究人员提供借鉴和参考。
2 主题模型概述
主题模型是一种语言模型,是文本挖掘领域中结合机器学习和自然语言处理等相关方法的一种统计模型,其基本思想认为文本是由多个主题混合而成的,而主题是特征词上的一种概率分布,即每篇文本是主题的混合分布,而每一个主题是一组特征词的混合分布[2]。同时,主题模型也是一种典型的生成概率模型,而生成模型指的是一篇文献的每个特征词都是通过“以一定的概率选择了某个主题,并从这个主题中以一定的概率选择了某个词汇”产生的,因而一篇文档中的特征词与其出现的概率可以表示为:
P(特征词|文档)=∑主题 P(特征词|主题)×P(主题|文档)
其中,P(特征词|文档)表示每个文档中每个特征词的出现概率;P(特征词|主题)表示每个主题中每个特征词的出现概率;P(主题|文档)表示每个文档中每个主题出现的概率。
主题模型起源于1990年Deerwester[3]提出的隐性语义索引(latent semantic indexing,LSI),其工作原理是利用奇异值分解技术实现文本维度的压缩,使得压缩后的潜在语义空间能够反映不同特征词之间的语义关系,但LSI不是概率模型,因而LSI并不算是主题模型。在LSI的基础之上,1999年Hofmann[4]提出概率隐含语义索引(probabilistic latent semantic indexing,pLSI),该模型通过引入概率模型,显式地对文本及其隐含主题进行建模,是第一个真正意义上的主题模型;但仍不是完整的概率模型,其参数只与训练文本相关,很难直接用于对新文本建模。随后,Blei等[5]又在pLSI的基础上提出了隐含狄利克雷分布模型(latent dirichlet allocation,LDA),该模型集成了pLSI的优点,同时也克服了pLSI的理论缺陷,并在之后被广泛应用于诸多领域。后来的学者也对该模型进行了扩展和改进,衍生出了层次概率主题模型(hierarchical topic model,hLDA)[6]、作者主题模型(author-topic,AT)[7,8,9]、动态主题模型(dynamic topic model,DTM)[10]等相关模型。
3 数据来源与研究方法
3.1 数据来源
本研究以Web of Science核心合集和中国学术期刊网络版(CNKI学术期刊全文数据库)为数据源,分别检索国际和国内发表的研究主题为“主题模型”的学术文献。考虑到第一个真正意义上的主题模型是Hofmann在1999年提出的pLSI模型,另外由于LDA模型是目前最常用的主题模型,也衍生出了诸多扩展和改进模型,因此,为保证检全,在设计检索式的过程中将pLSI和LDA也纳入检索词。在保证数据全面性的同时,由于部分检索词的多义性,笔者对初步的检索结果进行了评估和筛选,剔除不相关文献,以确保数据的准确性。最终检索得到国外数据库文献1 288篇,国内数据库文献865篇,检索细节见表1。
表1 文献检索策略
| 数据类型 | 检索日期 | 来源数据库 | 检索式 | 检索结果 |
|---|---|---|---|---|
| 国际数据 | 2017.1.1 | Web of Science 核心合集 | TS=(“topic model*” OR LDA OR “Latent Dirichlet Allocation” OR PLSA OR PLSI OR “probabilistic latent semantic”) AND 文献类型: (Article OR Letter OR Note OR Review) 不限时间跨度 | 1 288篇 |
| 国内数据 | 2017.1.1 | 中国学术期刊网络版(CNKI学术期刊全文数据库) | 主题(精确)=(主题模型 OR 主题建模 OR LDA模型 OR 潜在狄利克雷分布 OR 隐含狄利克雷分布 OR 潜在狄利克雷分配 OR 隐含狄利克雷分配 OR PLSA OR PLSI OR 概率潜在语义索引 OR 概率隐含语义索引 OR 概率潜在语义分析 OR 概率隐含语义分析) 不限时间跨度 | 865篇 |
3.2 研究方法及工具
本研究采用文献外部特征统计分析和共词分析方法对主题模型在国际和国内的研究发展态势和研究热点分布进行梳理和揭示。对于国外数据,将通过TDA软件抽取和统计文献外部特征,并对作者关键词进行自动和人工清洗,把同根词、同义词、近义词、单复数形式和复合形式进行合并,最终生成关键词的共词矩阵和相异矩阵;对于国内数据,将通过SATI软件完成抽取和分析工作,由于软件本身不具备关键词清洗的功能,因此,将采用半人工的方式进行数据清洗,以确保研究结果的可靠性。另外,使用专业统计软件SPSS 20.0对关键词矩阵进行聚类分析,值得注意的是,SPSS的系统聚类模块已经嵌入了相似度算法,若不对其进行阻止,则会在上述相异矩阵的基础上再进行一次相似度计算,造成对相似度的高估和扭曲。因而,需要在Syntax编辑窗口对Syntax进行编辑,阻止聚类模块在聚类之前重复计算相 似度[11]。
4 主题模型的研究发展态势
4.1 时间趋势分析
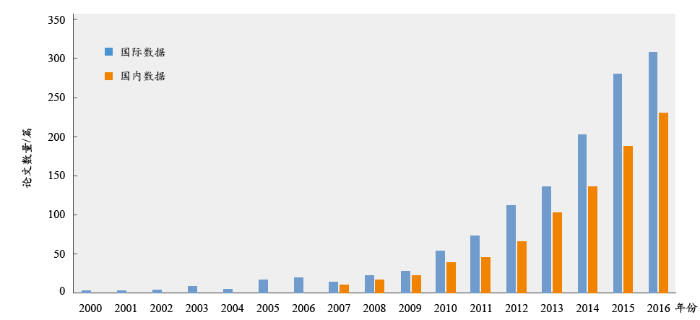
学术论文数量的时序变化,可以作为衡量某领域发展情况的一项指标[12]。通过对学术论文的发文时间进行统计,有助于了解该领域的发展脉络和趋势。从主题模型研究的发文时间分布情况(见图1)可以看出,国内外的主题模型研究从整体上均呈现增长态势,且增速相对较快。从发文情况的国外数据可以看出,在2005年以前,主题模型研究的总体发文较少,发文数量以个位数计,其中最早正式发表的期刊论文是2000年法国学者Bigi B等[13]撰写的“A fuzzy decision strategy for topic identification and dynamic selection of language models”,该文提出了一种基于模糊关系的主题模型,并通过主题分类精度验证了模型的有效性。从2005年开始,发文数量开始逐年上升,其中2015年发文共计282篇,2016年(截至2017年1月1日)已累计发文309篇。国内发文的时间分布与国外发文类似,国内学者自2005年开始在主题模型方面有所涉猎,最早发文的是华东师范大学的姚红玉等人[14],于2005年发表了“基于pLSA的智能学习支持系统”,该文对比了pLSA与LSA算法,阐明了pLSA算法的优势,并提出基于pLSA的学习支持系统的具体设计与实现。国内发文量的快速增长出现在2007年,起步相对滞后,但后续发展速度较快,表明国内学者对主题模型的研究热情在逐步提高。
图1
4.2 发文机构和作者分布
统计学术论文的发文机构和作者的分布情况,有助于研究人员了解该领域较为突出的研究机构和学者,帮助其明确自身所处的位置,找到标杆,从而进行有效的学习研究。
4.2.1 发文机构分布
对主题模型研究的发文机构进行统计排序,列举出发文量前10位的研究机构(见表2)。从国际发文情况来看,中国在TOP10的发文机构中占据7所,包括中国科学院、清华大学、浙江大学等,可见,中国作为后起之秀,在主题模型研究方面已成为国际上主要的研究群体,形成了一定的研究规模,对推动主题模型的发展起到了积极作用。另外3所TOP10发文机构分别是美国的加州大学欧文分校、卡内基梅隆大学和普林斯顿大学,这3所大学在计算机科学、数据分析和图书情报领域都具有较强的科研实力。从国内发文情况来看,武汉大学的发文数量最多,在文本分类、文本主题挖掘、遥感图像场景分类等方面均取得了一定的研究成果。另外,国内主题模型研究的二级发文机构相对集中,主要分布在高校计算机学院和图情学院,如武汉大学计算机学院和信息管理学院、苏州大学计算机科学与技术学院、中国科学院计算技术研究所等。
表2 主题模型研究的主要发文机构
| 国外数据库 | 国内数据库 | ||
|---|---|---|---|
| 机构名称 | 发文量/篇 | 机构名称 | 发文量/篇 |
| 中国科学院(中) | 61 | 武汉大学 | 69 |
| 清华大学(中) | 51 | 中国科学院 | 46 |
| 浙江大学(中) | 38 | 苏州大学 | 21 |
| 武汉大学(中) | 30 | 北京邮电大学 | 20 |
| 加州大学欧文分校(美) | 26 | 南京大学 | 20 |
| 香港城市大学(中) | 21 | 浙江大学 | 18 |
| 上海交通大学(中) | 21 | 南京理工大学 | 17 |
| 卡内基梅隆大学(美) | 19 | 吉林大学 | 17 |
| 北京航空航天大学(中) | 18 | 东北大学 | 15 |
| 普林斯顿大学(美) | 18 | 国防科学技术大学 | 15 |
4.2.2 作者分布
对主题模型研究的发文作者进行统计排序,列举出发文量最多的前10位作者(见表3)。从国际发文情况来看,发文最多的是清华大学计算科学与技术系的唐杰教授、美国罗特格斯州立大学的熊辉教授以及武汉大学测绘遥感国家重点实验室的张良培教授,分别发文12篇,他们的研究方向主要集中在社会网络分析、文本分类与推荐、遥感图像场景分类等方面,其他的高产作者还包括中国科学院自动化研究所的徐常胜研究员、印第安纳大学图书馆与信息科学学院丁颖博士等。从国内发文情况来看,发文最多的是武汉大学信息管理学院李湘东教授和苏州大学计算机科学与技术学院的严建峰教授,分别发文14篇和11篇,他们的研究方向主要集中在文本分类、并行LDA和消息传递算法等方面,其他的高产作者还包括苏州大学的刘晓升以及武汉大学的黄莉和唐晓波等。
表3 主题模型研究的主要作者
| 国外数据库 | 国内数据库 | ||||
|---|---|---|---|---|---|
| 作者 | 单位 | 发文量/篇 | 作者 | 单位 | 发文量/篇 |
| Tang, Jie | 清华大学 | 12 | 李湘东 | 武汉大学 | 14 |
| Xiong, Hui | 美国罗特格斯州立大学 | 12 | 严建峰 | 苏州大学 | 11 |
| Zhang, Liangpei | 武汉大学 | 12 | 刘晓升 | 苏州大学 | 8 |
| Xu, Changsheng | 中国科学院自动化研究所 | 11 | 黄 莉 | 武汉大学 | 8 |
| Ding, Ying | 印第安纳大学 | 10 | 唐晓波 | 武汉大学 | 7 |
| Huang, Zhengxing | 浙江大学 | 10 | 杨 璐 | 苏州大学 | 7 |
| Steyvers, Mark | 加利福尼亚大学欧文分校 | 10 | 杨 静 | 哈尔滨工程大学 | 7 |
| Tong, Weida | 美国食品及药物管理局 | 10 | 姬东鸿 | 武汉大学 | 7 |
| Gatica-Perez, Daniel | 瑞士洛桑联合理工大学 | 9 | 马 军 | 山东大学 | 6 |
| Dong, Wei | 中国人民解放军总医院 | 8 | 黄 宇 | 中国科学院电子学研究所 | 6 |
4.3 学科和期刊分布
统计学术论文的学科和期刊分布情况有助于研究人员了解该领域的学科交叉态势,明确重点相关的研究领域,同时还可以为其提供期刊投稿建议。其中,在分析论文的学科分布情况时,两种文献数据源的学科分类方式存在一定的差异:Web of Science核心合集采用的“Web of Science类别”共包含了生命科学与生物医学、自然科学、社会科学等5个大类252个小类;而CNKI数据库采用的文献学科分类则包括了基础科学、工程科技、农业科技等10个一级类168个二级类。
4.3.1 学科分布
对主题模型研究论文的学科分布进行统计,列举出发文量最多的前10个学科(见表4)。从中可以看出,计算机科学与技术是主题模型研究最活跃的学科,在国际发文中其他较为活跃的学科还包括工程学、图书情报学、数学、运筹与管理科学等,国内发文中其他较为活跃的学科还包括互联网技术、图书情报与数字图书馆、自动化技术、新闻与传媒等。由此可见,主题模型研究的学科分布呈现多样化趋势,该方法不断渗透并应用到其他学科当中,成为文本或其他形式数据挖掘和分类的有力工具。
表4 主题模型研究论文的学科分布
| 国外数据库 | 国内数据库 | ||
|---|---|---|---|
| 学科分类 | 文献量/篇 | 学科分类 | 文献量/篇 |
| 计算机科学(Computer Science) | 902 | 计算机软件及计算机应用 | 653 |
| 工程学(Engineering) | 305 | 互联网技术 | 103 |
| 信息科学与图书馆学 (Information Science & Library Science) | 100 | 图书情报与数字图书馆 | 50 |
| 数学(Mathematics) | 50 | 自动化技术 | 33 |
| 运筹与管理科学 (Operations Research & Management Science) | 48 | 新闻与传媒 | 27 |
| 电信学(Telecommunications) | 47 | 无线电电子学 | 15 |
| 数学与计算生物学 (Mathematical & Computational Biology) | 46 | 数学 | 14 |
| 医学信息学(Medical Informatics) | 46 | 自然地理学和测绘学 | 11 |
| 成像科学与摄影技术 (Imaging Science & Photographic Technology) | 42 | 电信技术 | 10 |
| 遥感学(Remote Sensing) | 42 | 工业通用技术及设备 | 8 |
4.3.2 期刊分布
对主题模型研究论文的发文期刊进行统计,分别列举了发文量最高的10种国内外期刊(见表5)。主题模型研究共涉及到了400余种国际期刊和300余种国内期刊,且期刊主要集中在计算机科学和图书情报领域。
表5 主题模型研究的主要发文期刊
| 国际期刊 | 国内期刊 | ||
|---|---|---|---|
| 期刊名称 | 发文量/篇 | 期刊名称 | 发文量/篇 |
| Neurocomputing | 38 | 计算机应用 | 54 |
| IEEE Transactions on Knowledge and Data Engineering | 36 | 计算机应用研究 | 42 |
| Expert Systems with Applications | 30 | 计算机科学 | 32 |
| Knowledge-Based Systems | 30 | 现代图书情报技术 | 31 |
| PLoS One | 26 | 计算机工程与应用 | 30 |
| IEEE Transactions on Pattern Analysis and Machine Intelligence | 25 | 计算机工程 | 26 |
| IEICE Transactions on Information and Systems | 23 | 图书情报工作 | 22 |
| BMC Bioinformatics | 21 | 计算机应用与软件 | 22 |
| Information Processing & Management | 21 | 小型微型计算机系统 | 19 |
| Multimedia Tools and Applications | 20 | 中文信息学报 | 18 |
5 主题模型的研究热点分布
关键词是作者对文章研究内容的直接概括,是文章主题的高度凝练。对文章关键词进行词频统计和聚类分析能够帮助研究人员梳理该领域的知识结构和研究热点,为今后开展相关研究提供参考和借鉴。
5.1 关键词词频统计
抽取主题模型研究论文的文章关键词,并通过软件和人工的方式进行关键词清洗,最终分别得到2 839个、2 312个关键词。经观察,选择频次≥9的国际发文关键词(共50个)和频次≥6的国内发文关键词(共50个)作为下一步聚类分析的基础,国际和国内发文关键词频次统计见表6。
表6 发文关键词频次统计(TOP20)
| 国外数据库 | 国内数据库 | ||
|---|---|---|---|
| 关键词 | 频次 | 关键词 | 频次 |
| 主题模型 | 469 | 主题模型 | 337 |
| LDA模型 | 230 | LDA模型 | 264 |
| 概率潜在语义分析 | 89 | 概率潜在语义分析 | 93 |
| 社交网络和媒体 | 89 | 微博 | 50 |
| 文本挖掘 | 54 | 文本分类 | 34 |
| 算法 | 35 | Gibbs抽样 | 28 |
| 推荐系统 | 31 | 聚类 | 20 |
| 语义分析 | 30 | 社交网络 | 20 |
| 信息检索 | 29 | 文本挖掘 | 19 |
| 实验 | 27 | 协同过滤 | 18 |
| 话题监测与跟踪 | 25 | 数据挖掘 | 18 |
| Gibbs抽样 | 25 | 文本聚类 | 18 |
| 数据挖掘 | 24 | 场景分类 | 17 |
| 语言模型 | 24 | 主题挖掘 | 17 |
| 无监督学习 | 24 | 支持向量机 | 16 |
| 聚类 | 23 | 特征选择 | 15 |
| 自然语言处理 | 22 | 情感分析 | 14 |
| 机器学习 | 21 | 自然语言处理 | 14 |
| 协同过滤 | 21 | 主题发现 | 14 |
| 场景分类 | 20 | 潜在语义分析 | 13 |
由表6可知,国际主题模型的研究内容主要集中在社交网络和媒体、推荐系统、信息检索、话题监测与跟踪等方面,而国内主题模型研究则主要集中在文本分类与聚类、社交网络、协同过滤、场景分类、情感分析等方面。
5.2 关键词聚类分析
表7 国际发文关键词相异矩阵(部分)
| 关键词 | 主题模型 | LDA模型 | 概率潜在 语义分析 | 社交网络 和媒体 | 文本 挖掘 | 算法 | 推荐 系统 | 语义 分析 | 信息 检索 | 实验 |
|---|---|---|---|---|---|---|---|---|---|---|
| 主题模型 | 0.000 | 0.750 | 0.966 | 0.770 | 0.855 | 0.836 | 0.859 | 0.882 | 0.923 | 0.867 |
| LDA模型 | 0.750 | 0.000 | 0.944 | 0.930 | 0.919 | 0.967 | 0.941 | 0.904 | 0.939 | 0.962 |
| 概率潜在语义分析 | 0.966 | 0.944 | 0.000 | 0.989 | 0.957 | 0.982 | 0.943 | 0.981 | 0.902 | 0.959 |
| 社交网络和媒体 | 0.770 | 0.930 | 0.989 | 0.000 | 0.899 | 0.803 | 0.924 | 0.865 | 1.000 | 0.796 |
| 文本挖掘 | 0.855 | 0.919 | 0.957 | 0.899 | 0.000 | 1.000 | 0.951 | 1.000 | 1.000 | 0.974 |
| 算法 | 0.836 | 0.967 | 0.982 | 0.803 | 1.000 | 0.000 | 1.000 | 0.969 | 1.000 | 0.219 |
| 推荐系统 | 0.859 | 0.941 | 0.943 | 0.924 | 0.951 | 1.000 | 0.000 | 1.000 | 1.000 | 1.000 |
| 语义分析 | 0.882 | 0.904 | 0.981 | 0.865 | 1.000 | 0.969 | 1.000 | 0.000 | 1.000 | 0.965 |
| 信息检索 | 0.923 | 0.939 | 0.902 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 0.000 | 1.000 |
| 实验 | 0.867 | 0.962 | 0.959 | 0.796 | 0.974 | 0.219 | 1.000 | 0.965 | 1.000 | 0.000 |
表8 国内发文关键词相异矩阵(部分)
| 关键词 | 主题模型 | LDA模型 | 概率潜在 语义分析 | 微博 | 文本 分类 | Gibbs 抽样 | 聚类 | 社交 网络 | 文本 挖掘 | 协同 过滤 |
|---|---|---|---|---|---|---|---|---|---|---|
| 主题模型 | 0.000 | 0.749 | 0.972 | 0.877 | 0.888 | 0.866 | 0.939 | 0.903 | 0.913 | 0.884 |
| LDA模型 | 0.749 | 0.000 | 0.994 | 0.826 | 0.799 | 0.837 | 0.945 | 0.876 | 0.901 | 0.942 |
| 概率潜在语义分析 | 0.972 | 0.994 | 0.000 | 0.985 | 1.000 | 1.000 | 0.861 | 0.977 | 1.000 | 0.927 |
| 微博 | 0.877 | 0.826 | 0.985 | 0.000 | 1.000 | 0.973 | 0.968 | 0.842 | 0.968 | 1.000 |
| 文本分类 | 0.888 | 0.799 | 1.000 | 1.000 | 0.000 | 0.903 | 0.962 | 1.000 | 1.000 | 1.000 |
| Gibbs抽样 | 0.866 | 0.837 | 1.000 | 0.973 | 0.903 | 0.000 | 1.000 | 0.958 | 0.870 | 1.000 |
| 聚类 | 0.939 | 0.945 | 0.861 | 0.968 | 0.962 | 1.000 | 0.000 | 1.000 | 1.000 | 0.947 |
| 社交网络 | 0.903 | 0.876 | 0.977 | 0.842 | 1.000 | 0.958 | 1.000 | 0.000 | 1.000 | 1.000 |
| 文本挖掘 | 0.913 | 0.901 | 1.000 | 0.968 | 1.000 | 0.870 | 1.000 | 1.000 | 0.000 | 1.000 |
| 协同过滤 | 0.884 | 0.942 | 0.927 | 1.000 | 1.000 | 1.000 | 0.947 | 1.000 | 1.000 | 0.000 |
图2
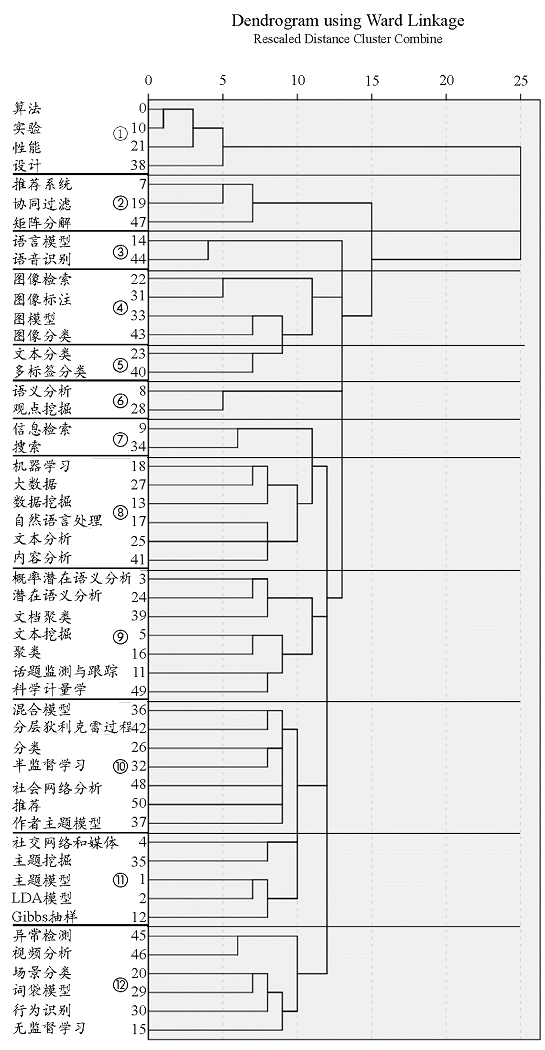
图3
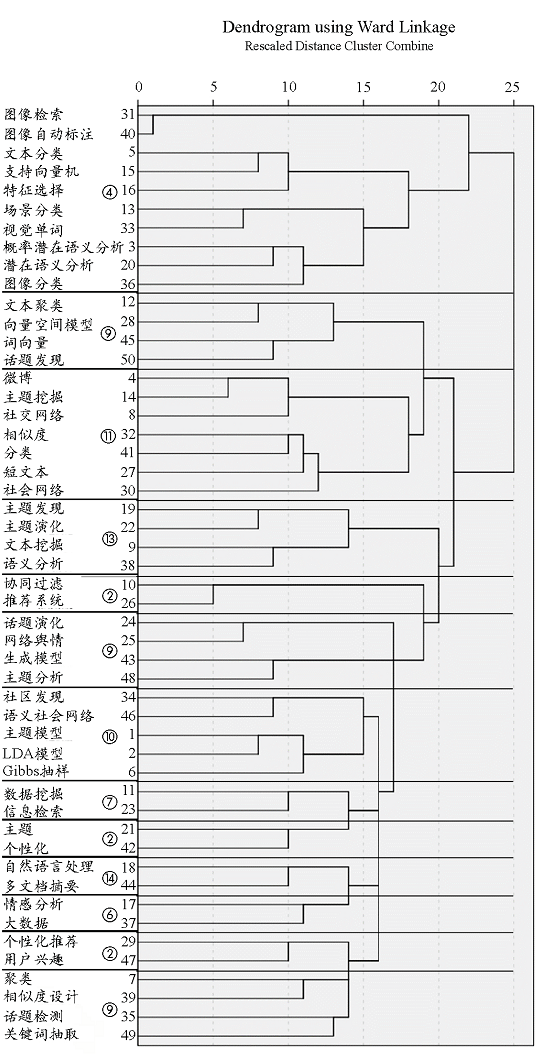
表9 主题模型领域研究热点分布
| 序号 | 主题标签 | 国际 | 国内 | 研究内容 |
|---|---|---|---|---|
| 1 | 主题模型 算法设计及性能优化 | √ | 随着主题模型的应用领域不断拓宽,最初的pLSI和LDA模型可能无法满足相应的研究需求,因而在pLSI和LDA模型的基础上进行改进和优化已成为当下的研究热点,如Chen, Kuan-Yu等提出了一套用于汉语拼写检查的概率框架,并通过实验验证其有效性[15]。 | |
| 2 | 协同过滤与 个性化推荐 | √ | √ | 协同过滤推荐算法由于其推荐的准确性和高效性已经成为推荐领域最流行的推荐算法之一,同时,将协同过滤推荐算法和主题模型相结合,可有效缓解数据稀疏性的问题,进一步提高推荐系统的准确性,如黄璐等将主题模型与协同过滤算法进行融合,用于移动应用的个性化推荐,保证了推荐的多样性和准确性[16]。 |
| 3 | 语音主题识别 | √ | 在现实环境中,不同个体的语言特征受到讲话风格、话题转变等多种因素的影响,对语音的主题识别带来了挑战,因此在动态环境下如何进行语音的主题识别和增量跟踪逐渐受到学者关注,如Watanabe, Shinji等提出了一种话题跟踪语言模型,能够基于当前环境的语音内容和前一时段训练完成的主题模型对话题转变进行探测[17]。 | |
| 4 | 图像分类、标注 与检索 | √ | √ | 随着互联网和图像技术的快速发展,越来越多的信息以图像的形式表达,而对海量的图像进行高效、可靠和智能化的分类和标注,则有助于人们便捷的获取到最有价值的内容,如曹洁等提出了融入类别信息的图像标注概率主题模型,利用图像类别来改进图像的标注性能,经验证,该模型的标注性能要高于相比较的模型[18]。 |
| 5 | 多标签分类 | √ | 多标签分类是指一个对象可能具有多个属性,且多个属性间可能存在一定的依赖和约束关系,近年来,不断有学者采用LDA及其扩展模型实现文档的多标签分类,如Li, Ximing等提出了一种有监督的主题模型算法LsTM,该算法具有两个优势,一是解释性强,二是可对词语进行多标签标注,而非单一标签[19]。 | |
| 6 | 情感分析和 观点挖掘 | √ | √ | 公众或消费者有关产品和服务的评价对企业改进产品和服务质量、其他消费者是否购买产品和服务有着重要的参考作用,而如何挖掘评论和意见中的核心观点和公众情感是当前的研究热点之一,如Cheng, Victor C等提出了一种生成概率模型PAMM,用于挖掘慢性疾病和药物的网络评论、博客和论坛中的核心观点,以辅助患者的治疗和用药[20]。 |
| 7 | 信息检索 | √ | √ | 通过主题模型挖掘文档的主题分布,计算与检索关键词主题之间的相似度,以此作为信息检索结果呈现的依据。相关研究如斯日古楞等提出了一种融合语言模型和LDA模型的方法,在充分利用蒙古文语法特征的基础上,实现快速准确的蒙古文信息检索[21]。 |
| 8 | 大规模数据挖掘 | √ | 网络数据的爆炸式增长对大规模数据挖掘技术提出了挑战,有关在线LDA模型、模型参数估计方法的优化和改进研究应运而生,如Zeng, Jia等提出了一种快速在线变分推理方法(FOEM),能够有效地对大规模文本数据进行快速建模和参数估计[22]。 | |
| 9 | 网络舆情 话题探测和跟踪 | √ | √ | 通过对网络舆情信息进行话题探测和跟踪,将话题以直观的方式呈现出来,便于公众对话题的来龙去脉有全面的了解,在政务、军事和民用方面具有重要的理论价值和现实意义。相关研究如赵华等对新浪微博和Twitter中有关H7N9的微博文本进行主题建模,以对比国内外H7N9话题的演化路径[24]。 |
| 10 | 社会网络分析 | √ | √ | 社会网络分析是对社会网络图以及其包含的额外信息的分析,近年来,在线社交网络的兴起,给社会网络分析带来新的挑战和机遇,其中链路预测和社区发现是社会网络分析的两个重要议题,如刘萍等运用社会网络理论,在社区划分的基础上,构建基于LDA的作者兴趣模型,对作者文献进行分析,达到科研合作推荐的目的[25]。 |
| 11 | 社交网络 主题挖掘 | √ | √ | 社交网络尤其是微博中含有大量的短文本,相对于传统文本,其语义特征信息密度较低,同时还带有一定的结构化社会网络信息,传统的文本挖掘方法不能很好的进行建模,而主题模型一定程度上解决了上述问题,如张晨逸等提出了一种基于LDA的微博生成模型MB-LDA,综合考虑了微博的联系人关联关系和文本关联关系,来辅助进行微博的主题挖掘[26]。 |
| 12 | 视频分析与 行为识别 | √ | 通过对视频场景进行主题建模,挖掘复杂人群中的群体行为,用于行为识别和异常检测,这对智能监控领域具有重要的现实价值。相关研究如Varadarajan, Jagannadan等提出了一种概率行为模型,能够挖掘长视频日志中的周期性行为序列模式[27]。 | |
| 13 | 科技文献 主题发现及演化 | √ | 通过对科技文献进行主题建模,了解某一领域的研究主题分布以及研究发展和演化脉络,把握该领域的研究热点和趋势,有助于科研人员更有针对性的开展相关研究,如王平利用层次概率模型hLDA进行科技文献的主题挖掘和主题变化识别,并通过实验验证了方法的有效性[28]。 | |
| 14 | 多文档摘要 | √ | 多文档摘要是指识别多篇同主题文档中的有用信息,压缩其中的冗余信息,生成一篇简短、流畅的摘要,以提高获取信息的效率,也是主题模型领域的研究热点之一,如邵洲等基于完全稀疏主题模型提出了一套自动摘要算法,有效解决了稀疏情况下的自动文档摘要问题,在推断时间和方法简便性等方面都具有优势[29]。 |
5.3 主题模型研究热点分析
由表9可知,国际和国内在主题模型领域所共有的研究热点包括7个,分别是:协同过滤和个性化推荐、图像分类标注和检索、情感分析和观点挖掘、信息检索、网络舆情话题探测和跟踪、社会网络分析和社交网络主题挖掘,这些研究热点不论是在国际还是国内都具有很高的关注度,是当下主题模型领域的重要研究课题。另外,国际和国内在主题模型领域的研究还存在以下差异:从研究层次上看,国内的研究多侧重于实际应用,理论方面的研究较少,在主题模型算法设计和性能优化、大规模数据挖掘方向上还有所欠缺,研究层次不够深入;从研究方法上看,除了最初的pLSI和LDA模型外,国际上还提出了作者-主题模型和分层狄利克雷过程等扩展模型,而国内在上述研究热点中未有涉及模型的扩展和优化,研究方法相对单一;从研究对象上看,国际上主题模型的研究对象包括文本、图像、语音、视频等多种类型的数据,而国内则主要是对文本和图像的研究,对语音和视频数据的研究相对较少,研究对象有待进一步扩展。
6 结语
面对信息的爆炸式增长和数据类型的多样化,常规的数理统计和数据挖掘方法难以进行有效的分析和处理,因而文本挖掘技术和主题模型方法应运而生,近年来受到了国内外学者的普遍关注,在多个领域获得广泛的应用。在这样的背景下,本文采用文献计量学中的文献外部特征统计分析和共词分析的方法,梳理和揭示了主题模型在国际和国内的研究发展态势和研究热点分布,研究结果如下:国际和国内的主题模型研究从整体上均呈现增长态势,且增速相对较快,其中,中国作为主题模型研究的后起之秀,在该领域已成为国际上主要的研究群体,对推动主题模型的发展起到了积极作用。另外,国际和国内在主题模型领域的研究既存在一致性也存在差异性,一致性主要体现在国际和国内拥有包括协同过滤和个性化推荐、图像分类标注和检索等在内的7个共同的研究热点,差异性则主要体现在国内主题模型研究层次不够深入、研究方法相对单一和研究对象有待进一步扩展3个方面。期望能够为相关研究人员提供借鉴和参考。
参考文献
Probabilistic topic models
[J].
Indexing by latent semantic analysis
[J].
Latent dirichlet allocation
[J].
Hierarchical topic models and the nested Chinese restaurant process
[J].
Learning author-topic models from text corpora
[J].
We propose an unsupervised learning technique for extracting information about authors and topics from large text collections. We model documents as if they were generated by a two-stage stochastic process. An author is represented by a probability distribution over topics, and each topic is represented as a probability distribution over words. The probability distribution over topics in a multi-author paper is a mixture of the distributions associated with the authors. The topic-word and author-topic distributions are learned from data in an unsupervised manner using a Markov chain Monte Carlo algorithm. We apply the methodology to three large text corpora: 150,000 abstracts from the CiteSeer digital library, 1740 papers from the Neural Information Processing Systems (NIPS) Conferences, and 121,000 emails from the Enron corporation. We discuss in detail the interpretation of the results discovered by the system including specific topic and author models, ranking of authors by topic and topics by author, parsing of abstracts by topics and authors, and detection of unusual papers by specific authors. Experiments based on perplexity scores for test documents and precision-recall for document retrieval are used to illustrate systematic differences between the proposed author-topic model and a number of alternatives. Extensions to the model, allowing for example, generalizations of the notion of an author, are also briefly discussed.
The reflection of hierarchical cluster analysis of co-occurrence matrices in SPSS
[J].
知识图谱研究的脉络, 流派与趋势——基于 SSCI 与 CSSCI 期刊论文的计量与可视化
[J].知识图谱作为快速兴起和发展的跨学科研究领域,在国内外不同学科间的发展轨迹、研究重点等方面总体上存在差异。适时梳理国内外该领域发展历史上的重要理论和技术发展轨迹,明晰核心人物和团队,可为当前和今后基于知识图谱的可视化研究提供理论基础。本文选取1998—2014年间SSCI、CSSCI中以知识图谱为主题的期刊论文,以SATI、UCINET、Net Draw、Cite Space等为数据分析和可视化工具,通过时间分布揭示该领域发展的阶段特征,通过节点性论文计算和高频关键词共现分析揭示该领域发展的内容分布,从而厘清其发展脉络;从学科分布、核心期刊和边缘期刊的判别揭示该领域发展的跨学科概貌,通过核心作者综合指数计算、合作分析和机构分析揭示该领域研究的人物关系,厘清其发展流派。在此基础上提出知识图谱研究的弱化与主题的衍生、知识图谱的跨学科研究与应用和知识创造者的合作创新三个发展趋势。图11。表3。参考文献29。
A fuzzy decision strategy for topic identification and dynamic selection of language models
[J].The paper introduces a new effective model for topic recognition. The model follows a multi-expert decision paradigm based on fuzzy relations in which fuzzy variables express degrees of reliability of expert decision. Heterogeneous measures are integrated by the fuzzy relations whose structure and components may evolve in time. Experiments resulted in more than 80% topic classification accuracy on articles of the French newspaper Le Monde which describe a very large variety of facts with a very large vocabulary (of the order of 500 000 words). Experiments show a significant improvement when the above mentioned integration of multi-expert decision is used. A robust strategy for dynamic language model (LM) selection, based on topic recognition and switching between topic models, is proposed. It is effective because it relies on a small set of well trained topic-dependent LMs and on reliable topic recognition. By using perplexity as a performance measure of the LM switching model, a tangible reduction is observed with respect to the use of a single, general, static LM.
基于PLSA的智能学习支持系统
[J].LPSS是由多种功能模块组成的智能学习支持系统,概率潜在语义分析PLSA是基于概率的一种新的潜在语义分析算法.文中对比论述了PLSA与LSA算法,并在此基础上分析了其他构建学习支持系统的方法,阐明PLSA相比于其他主主法的优势.提出了基于PLSA的学习支持系统的具体设计与实现.
基于SPSS的共现聚类分析参数选择的实例研究
[J].以OHSUMED语料库内提供的明确相关提问对为金标准和研究材料,借助BICOMB软件生成主题词一来源文献矩阵和共词矩阵,并获得各种系数的相似(相异)矩阵,对比分析目前国内基于SPSS共现聚类分析过程中主题词一来源文献矩阵与共现矩阵、各种相似性参数和各种类间距离计算方法的聚类效果。结果表明:主题词一来源文献矩阵聚类结果优于共词矩阵,在聚类分析中应优先选择。共词矩阵选择相似系数时应结合实际矩阵数据性质,并注意聚类方法原理上的正确性。
A probabilistic framework for Chinese spelling check
[J].Chinese spelling check (CSC) is still an unsolved problem today since there are many homonymous or homomorphous characters. Recently, more and more CSC systems have been proposed. To the best of our knowledge, language modeling is one of the major components among these systems because of its simplicity and moderately good predictive power. After deeply analyzing the school of research, we are aware that most of the systems only employ the conventional n-gram language models. The contributions of this article are threefold. First, we propose a novel probabilistic framework for CSC, which naturally combines several important components, such as the substitution model and the language model, to inherit their individual merits as well as to overcome their limitations. Second, we incorporate the topic language models into the CSC system in an unsupervised fashion. The topic language models can capture the long-span semantic information from a word (character) string while the conventional n-gram language models can only preserve the local regularity information. Third, we further integrate Web resources with the proposed framework to enhance the overall performance. Our rigorously empirical experiments demonstrate the consistent and utility performance of the proposed framework in the CSC task.
融合主题模型和协同过滤的多样化移动应用推荐
[J].随着移动应用的急速增长,手机助手等移动应用获取平台也面临着信息过载的问题.面对大量的移动应用,用户很难找到最适合的;而另一方面,长尾应用淹没在资源池中不易被人所知.已有推荐方法多注重推荐准确率,忽视了多样性,推荐结果中多是下载量高的应用,使得推荐系统的数据积累越来越偏向于热门应用,导致长期的推荐效果越来越差.针对这一问题,首先改进了两种推荐方法,提出了将用户的主题模型和应用的主题模型与MF相结合的LDA_MF模型,以及将应用的标签信息和用户行为数据同时加以考虑的LDA_CF算法.为了结合不同算法的优点,在保证推荐准确率的条件下提升推荐结果的多样性,提出了融合LDA_MF,LDA_CF以及经典的基于物品的协同过滤模型的混合推荐算法.使用真实的大数据评测所提推荐算法,结果显示,所提推荐方法能够得到推荐多样性更好且准确率更高的结果.
Topic tracking language model for speech recognition
[J].In a real environment, acoustic and language features often vary depending on the speakers, speaking styles and topic changes. To accommodate these changes, speech recognition approaches that include the incremental tracking of changing environments have attracted attention. This paper proposes a topic tracking language model that can adaptively track changes in topics based on current text information and previously estimated topic models in an on-line manner. The proposed model is applied to language model adaptation in speech recognition. We use the MIT OpenCourseWare corpus and Corpus of Spontaneous Japanese in speech recognition experiments, and show the effectiveness of the proposed method.
融入类别信息的图像标注概率主题模型
[J].基于概率主题模型的图像标注方法旨在通过学习图像语义进行图像标注,近年来倍受研究人员关注。考虑到类别对图像标注可提供有价值的信息,例如,“高楼”类图像,出现“天空”、“摩天楼”的可能性大于“海水”和“沙滩”。而“海岸”类图像出现“海水”、“沙滩”的可能性要大于“天空”和“摩天楼”。在Corr-LDA模型的基础上利用图像类别来改进图像的标注性能,提出了一个融入类别信息的图像标注概率主题模型。为该模型推导了一个基于变分EM的参数估计算法,并给出了使用该模型标注图像的方法。在LabelMe和UIUC-Sport两个真实数据集上验证了提出模型的标注性能要高于其他相比较模型。
Labelset topic model for multi-label document classification
[J].It has recently been suggested that assuming independence between labels is not suitable for real-world multi-label classification. To account for label dependencies, this paper proposes a supervised topic modeling algorithm, namely labelset topic model (LsTM). Our algorithm uses two labelset layers to capture label dependencies. LsTM offers two major advantages over existing supervised topic modeling algorithms: it is straightforward to interpret and it allows words to be assigned to combinations of labels, rather than a single label. We have performed extensive experiments on several well-known multi-label datasets. Experimental results indicate that the proposed model achieves performance on par with and often exceeding that of state-of-the-art methods both qualitatively and quantitatively.
Probabilistic aspect mining model for drug reviews
[J].Recent findings show that online reviews, blogs, and discussion forums on chronic diseases and drugs are becoming important supporting resources for patients. Extracting information from these substantial bodies of texts is useful and challenging. We developed a generative probabilistic aspect mining model (PAMM) for identifying the aspects/topics relating to class labels or categorical meta-information of a corpus. Unlike many other unsupervised approaches or supervised approaches, PAMM has a unique feature in that it focuses on finding aspects relating to one class only rather than finding aspects for all classes simultaneously in each execution. This reduces the chance of having aspects formed from mixing concepts of different classes; hence the identified aspects are easier to be interpreted by people. The aspects found also have the property that they are class distinguishing: They can be used to distinguish a class from other classes. An efficient EM-algorithm is developed for parameter estimation. Experimental results on reviews of four different drugs show that PAMM is able to find better aspects than other common approaches, when measured with mean pointwise mutual information and classification accuracy. In addition, the derived aspects were also assessed by humans based on different specified perspectives, and PAMM was found to be rated highest.
融合主题与语言模型的蒙古文信息检索方法研究
[J].为了从日益丰富的蒙古文信息中快速准确地检索用户需求的主题信息,提出了一种融合主题模型LDA与语言模型的方法。该方法用语言模型与LDA模型对蒙古文文档进行建模,利用吉普斯抽样方法进行推理间接计算模型的参数,挖掘隐藏在文档内不同主题与词之间的关系,得到文档的主题分布,并以此分布来计算与检索关键词主题之间的相似度,最后返回与该主题最相关的文档。语言模型充分利用蒙古文语法特征以及统计信息,而主题模型LDA又具有良好的潜在语义挖掘及主题发现的泛化学习能力,从而结合两种方法更好地实现蒙古文文档的主题语义检索,提高检索准确性。实验结果表明,融合LDA与语言模型的方法相比单一模型体现主题语义方面取得了较好的效果。
Fast online EM for big topic modeling
[J].The expectation-maximization (EM) algorithm can compute the maximum-likelihood (ML) or maximum a posterior (MAP) point estimate of the mixture models or latent variable models such as latent Dirichlet allocation (LDA),which has been one of the most popular probabilistic topic modeling methods in the past decade. However, batch EM has high time and space complexities to learn big LDA models from big data streams. In this paper, we present a fast online EM (FOEM) algorithm that infers the topic distribution from the previously unseen documents incrementally with constant memory requirements. Within the stochastic approximation framework, we show that FOEM can converge to the local stationary point of the LDA likelihood function. By dynamic scheduling for the fast speed and parameter streaming for the low memory usage, FOEM is more efficient for some lifelong topic modeling tasks than the state-of-the-art online LDA algorithms to handle both big data and big models (aka, big topic modeling) on just a PC.
中英文突发事件话题演化对比研究
[J].<p>文章从新浪微博和Twitter抓取突发事件语料,根据主题模型确定候选话题,通过对候选话题进行聚类确定更为合适的话题数,然后根据主题模型结果计算相邻时间片话题之间的相似度,在此基础上分析话题的演化,最终完成中英文话题演化的比较分析。文章针对H7N9微博的实证结果表明:新浪微博话题数目较多,话题面更为广泛;国内对H7N9禽流感事件的爆发反应更为强烈;两个平台在话题内容方面也存在一些差异;另外,两个平台话题演化的可视化结果可以描述H7N9禽流感事件新话题的产生、旧话题的消亡以及话题内容随时间的变化。</p>
基于LDA模型的科研合作推荐研究
[J].为了更准确更合理地进行科研合作推荐,文章运用社会网络理论,在社区划分的基础上,构建基于LDA的作者兴趣模型,然后对作者的相关文献进行分析,实现科研合作推荐的目的。实验证明,该方法能够有效地进行科研合作的推荐。
基于MB-LDA模型的微博主题挖掘
[J].随着微博的日趋流行,Twitter等微博网站已成为海量信息的发布体,对微博的研究也需要从单一的用户关系分析向微博本身内容的挖掘进行转变.在数据挖掘领域,尽管传统文本的主题挖掘已经得到了广泛的研究,但对于微博这种特殊的文本,因其本身带有一些结构化的社会网络方面的信息,传统的文本挖掘算法不能很好地对它进行建模.提出了一个基于LDA的微博生成模型MB-LDA,综合考虑了微博的联系人关联关系和文本关联关系,来辅助进行微博的主题挖掘.采用吉布斯抽样法对模型进行推导,不仅能挖掘出微博的主题,还能挖掘出联系人关注的主题.此外,模型还能推广到许多带有社交网络性质的文本中.在真实数据集上的实验表明,MB-LDA模型能有效地对微博进行主题挖掘.
A sequential topic model for mining recurrent activities from long term video logs
[J].This paper introduces a novel probabilistic activity modeling approach that mines recurrent sequential patterns called motifs from documents given as word \(\times \) time count matrices (e.g., videos). In this model, documents are represented as a mixture of sequential activity patterns (our motifs) where the mixing weights are defined by the motif starting time occurrences. The novelties are multi fold. First, unlike previous approaches where topics modeled only the co-occurrence of words at a given time instant, our motifs model the co-occurrence and temporal order in which the words occur within a temporal window. Second, unlike traditional Dynamic Bayesian networks (DBN), our model accounts for the important case where activities occur concurrently in the video (but not necessarily in synchrony), i.e., the advent of activity motifs can overlap. The learning of the motifs in these difficult situations is made possible thanks to the introduction of latent variables representing the activity starting times, enabling us to implicitly align the occurrences of the same pattern during the joint inference of the motifs and their starting times. As a third novelty, we propose a general method that favors the recovery of sparse distributions, a highly desirable property in many topic model applications, by adding simple regularization constraints on the searched distributions to the data likelihood optimization criteria. We substantiate our claims with experiments on synthetic data to demonstrate the algorithm behavior, and on four video datasets with significant variations in their activity content obtained from static cameras. We observe that using low-level motion features from videos, our algorithm is able to capture sequential patterns that implicitly represent typical trajectories of scene objects.
基于层次概率主题模型的科技文献主题发现及演化
[J].自动挖掘科技文献主题并识别主题变化对于科研工作者及时获取相关领域的最新研究动态有着重要作用。针对科技文献主题多样、动态性强等特点,分析科技文献主题发现及演化具体方法,基于层次概率主题模型 hLDA,采用 Gibbs抽样来进行模型参数估计,并运用互信息的方法对主题词进行筛选,以提取高质量的主题词。最后,利用先/后离散分析方法研究主题随时间的演化问题。实验结果验证了主题发现及演化方法的可行性及有效性。

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}